La dépendance peut se définir comme la nécessité pour une personne âgée de recourir à une tierce personne pour accomplir les actes élémentaires de la vie quotidienne (Duée et Rebillard, 2004). Les études montrent que l'incidence de la dépendance s'accroît fortement avec l'âge (Gisserot et Grass, 2007). En France, un individu ayant atteint l'âge de soixante-cinq ans a une probabilité avoisinant les 15 % de connaître un épisode de dépendance lourde avant son décès (Rosso-Debord, 2010) et une probabilité d'environ 40 % de connaître un épisode de dépendance lourde ou légère (OCDE, 2005). Ainsi, le vieillissement de la population va vraisemblablement accroître la population dépendante et la demande de soins (Duée et Rebillard, 2004). Au-delà de la perte de bien-être occasionnée par la survenance de cet état, la dépendance représente un risque financier important : en moyenne, le reste à charge est d'environ 1 800 euros par mois (Rosso-Debord, 2010). L'aide sociale représentée par l'Aide personnalisée d'autonomie (APA), dont le montant moyen est 409 euros, n'en représente que 30 % (Ennuyer, 2006). Il reste ainsi un complément important à la charge de la personne dépendante ou de sa famille, et supérieur au montant moyen des retraites : 979 euros pour les femmes et 1 625 euros pour les hommes1. Cependant, le marché de l'assurance dépendance est encore peu développé. Environ 10 % des plus de quarante ans sont actuellement couverts par un produit dépendance (tous types de couvertures confondus). Par comparaison, le taux d'équipement de la complémentaire santé en France est de 86 % (HCAAM, 2005). Le fait que le marché ne se développe pas davantage peut apparaître comme une véritable « énigme » (Kessler, 2007). L'objectif de notre étude est d'apporter une réponse à cette « énigme de l'assurance dépendance ».
Les principaux travaux empiriques sur la demande d'assurance ont été réalisés jusqu'à présent sur les marchés américain et espagnol (Sloan et Norton, 1997 ; Finkelstein et McGarry, 2006 ; Costa-Font et Rovira-Forns, 2008). En raison de contextes institutionnels assez éloignés du cas français, ces résultats sont difficilement transposables. À notre connaissance, il n'existe à ce jour que deux études empiriques sur le marché français (Courbage et Roudaut, 2007 ; Fontaine et al., 2015). Ces deux travaux présentent la particularité de se baser sur des données déclaratives et non sur des données d'assureurs ou de bancassureurs. Nous avons pu accéder aux données de l'un des plus gros bancassureur français, leader sur le produit dépendance. En tant que données bancaires, et cela constitue une certaine originalité, ces données renseignent sur le revenu et le patrimoine des individus, observés en clair et non de manière déclarative comme avec l'enquête SHARE.
Revue de littérature
Plusieurs explications relatives à l'offre et à la demande de couverture ont essayé de rendre compte de cette « énigme de l'assurance dépendance » (Kessler, 2007).
Les explications relatives à l'offre
Les premiers travaux sur l'offre d'assurance ont observé une incomplétude du marché. Ainsi, les assureurs ne proposeraient qu'un seul produit en rente, ce qui désinciterait les individus à s'assurer (Cutler, 1993). Par ailleurs, si l'aléa moral ne semble pas se vérifier sur le marché américain, un phénomène d'antisélection n'est pas à exclure (Sloan et Norton, 1997). Sur le marché américain, les mauvais risques semblent davantage s'assurer. Ce phénomène semble compensé par le fait que les personnes les plus averses s'assurent davantage et ce sont elles qui investissent le plus dans la prévention, diminuant leur probabilité de devenir dépendant (Finkelstein et McGarry, 2006). Mais comme le remarquent Brown et Finkelstein (2008), les explications par les manquements de l'offre sont insuffisantes et il convient aussi de se demander pourquoi la demande d'assurance dépendance est si faible.
Les explications relatives à la demande
Les attitudes de myopie face au risque ou les idées fausses sur l'étendue de l'assurance publique semblent de moins en moins vérifiées concernant le risque dépendance en France (Institut CSA, 2006).
Une autre raison expliquant la faible demande d'assurance privée réside dans l'effet d'éviction exercé par l'aide publique. Des travaux ont montré que cet effet d'éviction était relativement important sur le marché américain et que l'aide publique exerçait une taxe implicite sur l'assurance privée (Brown et Finkelstein, 2008).
D'autres auteurs ont avancé l'idée que la demande d'assurance dépendance était victime d'un aléa moral intergénérationnel (Zweifel et Struve, 1996) : les enfants seraient moins soucieux de la situation de leurs parents lorsque ces derniers ont souscrit un contrat dépendance. Afin de se prémunir contre le fait que les enfants ne s'occupent pas d'eux en cas de survenance, les parents ne seraient pas incités à souscrire.
Des travaux récents ont également montré le rôle des préférences dans la souscription d'une assurance dépendance et notamment le rôle de la préférence pour le présent (Fontaine et al., 2015).
Les données
La population étudiée
Les données utilisées sont issues d'une grande banque française proposant à ses clients des produits d'assurance dépendance et représentant environ 20 % du marché de l'assurance dépendance (Decoster, 2006) avec des agences réparties uniformément sur toute la France.
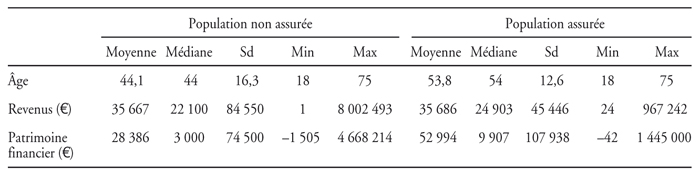
De 2002 à 2006, cette banque propose à chacun de ses clients bancaires en mesure de souscrire (18-75 ans) une police d'assurance dépendance individuelle. Les clients ont été soumis à la même politique commerciale car les commerciaux ne disposaient pas à l'époque d'outils de ciblage-clientèle. Nous raisonnons sur un portefeuille clients provenant d'une seule compagnie d'assurances, puisque le scoring n'est applicable que si tous les clients ont été démarchés commercialement de la même manière (Lebart, 1971). Nous avons obtenu pour notre étude des données de la région « Centre ». Sur les 275 257 personnes assurables dans le portefeuille de cette région, 5 027 ont accepté de souscrire (1,82 % du portefeuille clients). Nous avons eu accès à un échantillon représentatif de 37,45 % du portefeuille de personnes non assurées (un tirage effectué par le fournisseur restitue un échantillon parfaitement aléatoire de 101 205 individus issus de la base de données des clients bancaires non assurés) et à l'intégralité des 5 027 clients assurés.
Le principal avantage des données auxquelles nous avons eu accès est qu'elles ne correspondent pas à des préférences déclarées, mais à des préférences révélées. Contrairement aux enquêtes par questionnaire, nous n'avons donc pas besoin d'intégrer le taux de participation ou le taux de retour car tous les clients ont été contactés et ont répondu. Il n'y a donc pas de biais dans notre étude qui seraient dus à la surparticipation de certaines catégories socioprofessionnelles (CSP) (en particulier les plus éduqués) propre aux enquêtes par questionnaire. En revanche, la nature exhaustive de ces données implique que nous disposons de moins de variables que dans les enquêtes déclaratives, ce qui rend possible l'existence de biais qui seraient liés ici à des variables non observables. À noter que dans notre étude qualifiée ainsi d'exploratoire, seul 2 % environ de la population étudiée s'assure contre la dépendance. Aussi, comme il s'agit d'une banque qui commercialise des produits d'assurance par sa filiale, nous avons accès aux données bancaires, ce qui est rarement le cas avec les assureurs qui ne disposent le plus souvent que de données actuarielles. Parmi l'ensemble des articles de référence faisant intervenir des données exhaustives, très peu d'auteurs (Brown et Finkelstein, 2007) font intervenir des données sociales et de santé.
Notre article ne réalise pas une extrapolation des résultats obtenus à la population française au sens strict du terme, mais dégage une tentative d'explication vraisemblable à l'échelle de cette population. Les exemples d'articles scientifiques ne manquent pas quand il s'agit de réaliser des études sur des échantillons non nationaux afin de dégager des tentatives d'explication à l'échelle nationale : Krieger et al. (1999), Nayaradou et al. (2010), Pornet et al. (2010), Bryere et al. (2014). Des tests de représentativité ont été effectués afin de tester la représentativité statistique des clients du portefeuille bancaire par rapport à la population de la région « Centre » recensée par l'Insee, cela en fonction des variables étudiées dans l'article : seule la variable « revenu » est non représentative.
Les caractéristiques du contrat d'assurance
Le contrat dépendance commercialisé est un contrat en rente. Nous modélisons la participation, c'est-à-dire le fait d'accepter la souscription ou de la refuser. La personne peut souscrire jusqu'à l'âge de soixante-quinze ans, pour un montant de rente défini à la souscription. Sur la période considérée, la rente minimale était de 600 euros par mois et pouvait atteindre 3 500 euros. La cotisation mensuelle payée par l'assuré dépend de son âge au moment de la souscription et du montant des prestations que l'assuré souhaite recevoir en cas de survenance. Lorsque son niveau de dépendance est certifié par l'unité médicale régionale en relation avec la filiale d'assurance de la banque, l'assuré cesse de payer ses cotisations et reçoit la rente lui permettant de financer ses soins, qui ne dépend pas du niveau de dépenses de ses soins, mais de la prime payée. Dans notre étude, le contrat couvre des besoins liés à un état de dépendance lourde correspondant aux niveaux GIR 1 et 2 (Groupe Iso Ressource).
Les variables explicatives
- Sexe : hommes et femmes.
- Âge : les individus ayant souscrit un contrat avaient nécessairement entre dix-huit ans et soixante-quinze ans au moment de la signature du contrat.
- Catégorie socioprofessionnelle : notre base de données nous fournit une information fiable en ce qui concerne le responsable financier du compte qui lorsqu'il souscrit, le fait dans l'extrême majorité des cas pour lui-même ou en tant que porteur du risque. C'est un bon indicateur du niveau d'éducation. Elle se décompose en sept sous-variables binaires d'appartenance (agriculteurs, commerçants, cadres supérieurs, cadres moyens, employés, ouvriers, sans activité).
- Revenu : variable correspondant aux sommes perçues annuellement sur le compte courant.
- Patrimoine financier : cette variable reflète le patrimoine financier et n'inclut pas le patrimoine immobilier.
Méthode d'estimation
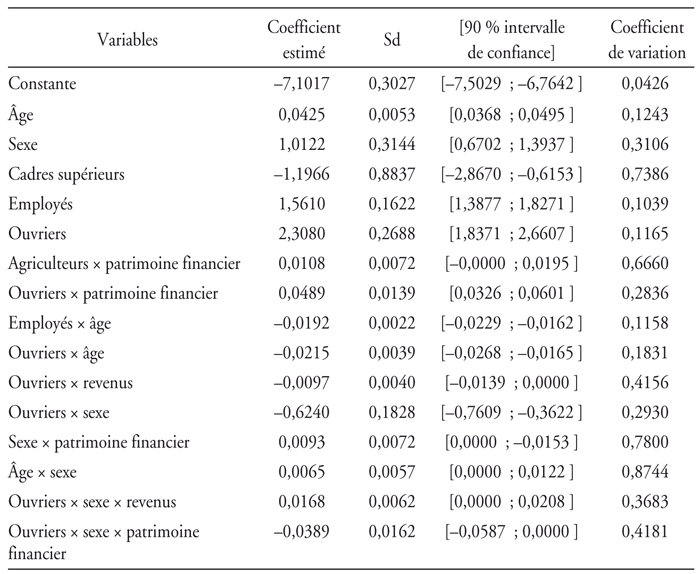
Nous utilisons un modèle logistique couplé à la méthode Bootstrap, afin d'évaluer l'impact des variables explicatives dont nous disposons sur la probabilité de souscrire à un contrat dépendance. Pour un individu i, la probabilité Pi qu'il accepte la souscription à l'assurance dépendance est fonction de son vecteur de variables explicatives précitées.
Nous avons eu accès à l'ensemble des détenteurs d'assurance, c'est-à-dire 5 027 individus, ainsi qu'à leurs caractéristiques, mais nous disposons de seulement 37,45 % de personnes non assurées (autrement dit 101 205 personnes). Il convient tout d'abord d'estimer le modèle avec une affectation de poids sur les personnes non assurées. Dans le modèle simple (avec seulement les sept variables explicatives de base) et dans le modèle avec effets croisés (les sept variables plus des croisements entre les sept variables décrites ci-avant), nous avons affecté la pondération 1 à chacun de nos assurés et la pondération de 2,67 (soit 1/37,45 %) à chacun de nos individus non assurés. La validation basée sur la technique Bootstrap permet ensuite de confirmer les résultats obtenus en termes d'estimations pour le modèle simple et le modèle avec effets croisés. En effet, notre segmentation est bien réelle et représentative de la population générale, mais déséquilibrée d'un point de vue statistique : la très faible proportion d'assurés de notre portefeuille (1,82 %) risque de fausser nos estimations. Nous devons donc vérifier en utilisant le Bootstrap que les facteurs dégagés dans ces deux modèles sont réellement significatifs afin d'éviter les effets de taille. Pour cela nous construisons vingt sous-échantillons de notre portefeuille, nous conduisant à estimer vingt modèles simples non pondérés et vingt modèles avec effets croisés non pondérés, nous permettant ainsi de construire des intervalles de confiance à 90 % relatifs à l'estimation des coefficients de nos variables explicatives. Chacun de ces sous-échantillons est constitué des 37,45 % disponibles des non-titulaires de police auxquels on associe une sélection aléatoire de 37,5 % de la totalité des assurés. Nous estimons le modèle Bootstrap avec effets principaux et avec effets croisés, dans les deux cas sur la base de ces vingt sous-échantillons. Ensuite, nous étudions le coefficient de variation (CV) associé à chaque variable significative, qui est relativement faible ou acceptable (cf. annexe), ce qui confirme nos résultats. De plus, les valeurs des coefficients sont proches de celles du modèle pondéré (avec effets principaux et effets croisés). Les modèles ont été définitivement validés par le critère de la corrélation des rangs et le test de Hosmer-Lemeshow (2000, consistant à évaluer la concordance entre proportions prédites par probabilités et celles observées, et ce, par quantiles).
Les résultats empiriques
Le modèle simple estimé par la méthode avec poids nous donne une première série de résultats qui tendent à expliquer un comportement rare à l'aide de variables relativement générales. Nos estimations ne nous permettent pas d'identifier des variables explicatives très fortement discriminantes, ainsi les individus qui s'assurent ne représentent pas une population très particulière. Le contrat dépendance n'apparaît donc pas comme un contrat de niche, mais potentiellement comme un contrat de masse, compte tenu de l'appétence relativement plus forte des ouvriers et des employés pour ce type de produits.
Les femmes s'assurent davantage que les hommes
Nous notons que les femmes s'assurent plus, cela en concordance avec les résultats obtenus par Costa-Font et Rovira-Forns (2008) et Fontaine et al. (2015).
Un effet prix pourrait être à l'origine de ce comportement, les femmes présentant des taux de prévalence plus élevés que les hommes. À chaque fois que le niveau de prime ne dépend pas du sexe, les taux de chargement (écarts relatifs entre les primes commerciales et les primes pures) sont beaucoup plus faibles pour les femmes. Sur le marché américain, Brown et Finkelstein (2007) ont observé que le prix pratiqué pour les femmes était souvent plus attractif que le prix actuariel. Ce type de comportement peut donc sembler rationnel.
Un effet de sélection peut également s'ajouter à l'effet prix. Même si la prime était différenciée, les femmes pourraient davantage s'assurer du fait de leur probabilité de sinistre plus élevée (effet de sélection) et de leur probabilité plus faible de recevoir de l'aide informelle, ce qui irait dans le sens de Pauly (1990). Enfin, ces différences de comportement face à l'assurance entre hommes et femmes pourraient être l'expression d'un degré d'aversion aux risques différent.
Les personnes âgées s'assurent davantage que les individus « jeunes »
L'âge exerce deux effets contraires sur la demande d'assurance dépendance :
- un effet « proximité du risque » qui devrait inciter les plus âgés à s'assurer davantage ;
- un effet prix qui devrait inciter les plus âgés à moins s'assurer.
L'effet « proximité du risque » devrait inciter les plus âgés à s'assurer davantage. Plus les gens sont jeunes et plus leur probabilité d'être dépendant à court terme est faible (Duée et Rebillard, 2004). L'effet prix devrait, quant à lui, agir en sens contraire. Plus les individus souscrivent une assurance à un âge élevé, plus la prime est élevée en échange d'un même montant de garantie. L'âge est en effet un bon proxy du prix de l'assurance. Courbage et Roudaut (2007) montrent que la probabilité de s'assurer varie négativement avec l'âge, ce qui laisse à penser que lorsque l'âge augmente, l'effet prix l'emporterait sur la « proximité du risque » chez les Français.
Nos résultats affichent que la probabilité de souscrire augmente avec l'âge, ce qui est cohérent avec les travaux récents menés sur le marché français (Fontaine et al., 2015). Nous observons en revanche une différence entre notre étude et celle de Costa-Font et Rovira-Forns (2008), observant une plus grande préférence pour l'assurance dépendance chez les populations jeunes. Notre étude suggère donc que le prix n'est pas une variable fondamentale dans la prise de décisions de souscrire. L'élasticité-prix de la demande d'assurance dépendance serait donc relativement faible. Il semble que l'approche du risque (le fait que l'âge avance) incite les individus à souscrire. Ainsi, nos résultats vont dans le même sens que ceux des prévisions théoriques de Meier (1998), montrant que les populations d'âges jeunes et intermédiaires sont moins enclines à souscrire.
Les ouvriers et les employés s'assurent davantage que les cadres
La CSP est, quant à elle, susceptible de capturer au moins trois types d'effets sur la demande d'assurance :
- un « effet information » via le niveau d'études fortement corrélé à la CSP ;
- un effet revenu via la forte corrélation entre CSP et revenu ;
- un effet de sélection via la corrélation négative entre CSP et probabilité de devenir dépendant.
L'effet information de la CSP devrait agir positivement sur la demande d'assurance dépendance. La CSP est en effet un bon proxy du niveau d'études. Or plus les individus sont éduqués et plus ils bénéficient d'un accès à l'information, plus ils ont conscience du risque dépendance. Ainsi, les comportements de myopie face au risque devraient diminuer avec le niveau d'études (« effet information »).
Si l'on suppose que la CSP est un bon proxy du niveau d'éducation, la probabilité de souscrire décroît alors avec le niveau d'éducation. En effet, dans notre étude, les agriculteurs, les ouvriers et les employés s'assurent plus que les cadres moyens et les cadres supérieurs. Ce résultat est encore renforcé par le fait que les retraités (les personnes les plus âgées) qui s'assurent sont, le plus souvent, d'anciens ouvriers ou employés (à 80 %). Il semblerait donc que le produit dépendance soit plutôt un produit à destination des ouvriers et des employés que des classes supérieures. Nos résultats sont contraires à ceux de McCall et al. (1998) et de Kumar et al. (1995), pour qui la probabilité de souscrire est positivement corrélée avec le niveau d'éducation. Mais ces études sont effectuées dans un contexte institutionnel américain qui est très différent du contexte français dans la mesure où les CSP+ ne sont pas couvertes par l'assurance sociale dans le cadre américain. En revanche, nos résultats sont conformes avec les dernières études empiriques effectuées sur le marché français (Fontaine et al., 2015). Il est intéressant de noter que Fontaine et al. observent que les CSP+ s'assurent moins que les employés et les ouvriers, alors même que les CSP+ sont davantage conscientes du risque dépendance.
Dans notre étude, les ouvriers ont 2,5 fois plus de chance de souscrire qu'un individu n'appartenant pas à cette catégorie, les employés ont 1,6 fois plus de chance et les cadres supérieurs 2,5 fois moins de chance. Les ouvriers et les employés semblent par conséquent avoir une sensibilité particulière au risque de dépendance.
Ce résultat reste à nuancer dans la mesure où il existe un biais potentiel que nos données ne nous permettent pas de mesurer. Les CSP+ recourent en général à davantage d'institutions financières que les employés et les ouvriers pour gérer leur épargne ou pour s'assurer. Il est donc possible que les CSP+ s'assurent davantage que les employés et les ouvriers auprès d'une autre institution que leur banque. Or nous ne disposons pas d'éléments dans nos données qui nous permettent de mesurer ce biais. Cependant, le fait que d'autres études montrent que les CSP+ s'assurent moins que les ouvriers et les employés nous laisse penser que ce biais non mesuré dans notre étude devrait rester limité.
L'effet du revenu
Le revenu peut théoriquement produire deux effets contraires sur la demande d'assurance :
- l'auto-assurance augmentant avec la richesse, les hauts revenus sont incités à moins s'assurer ;
- l'effet d'éviction de l'aide sociale diminuant avec la richesse, il désincite moins les hauts revenus à s'assurer que les bas revenus.
Nos résultats ne nous permettent pas de retenir l'un des deux effets mentionnés plus haut. Cela peut s'expliquer soit par le fait que le revenu n'exerce réellement pas d'effet sur la probabilité de souscription, soit que les deux effets mentionnés précédemment s'annulent.
Les individus possédant du patrimoine s'assurent davantage que ceux de la population générale
L'assurance dépendance peut servir à assurer son patrimoine et par suite préserver le montant de l'héritage à transmettre. Les individus peuvent préférer payer une assurance plutôt que de courir le risque d'avoir à désépargner pour financer leur dépendance. Nos résultats montrent que la présence d'un patrimoine augmente la probabilité de souscription. L'assurance pourrait donc être perçue comme un moyen d'assurer son patrimoine. Cependant, l'effet du patrimoine est encore plus intéressant lorsqu'on retient des effets croisés parmi les variables explicatives. Le modèle simple montre que les personnes qui souscrivent le plus sont les femmes, les ouvrières et âgées. Celui avec effets croisés montre que chez les agriculteurs, les ouvriers ainsi que chez les femmes, une élévation du patrimoine implique une augmentation de la probabilité de souscription.
Résultats complémentaires apportés par les effets croisés
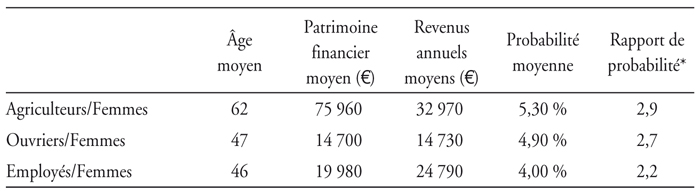
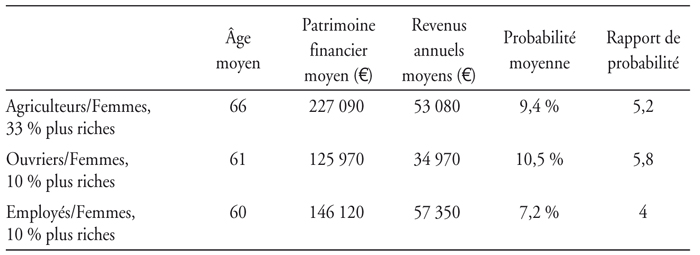
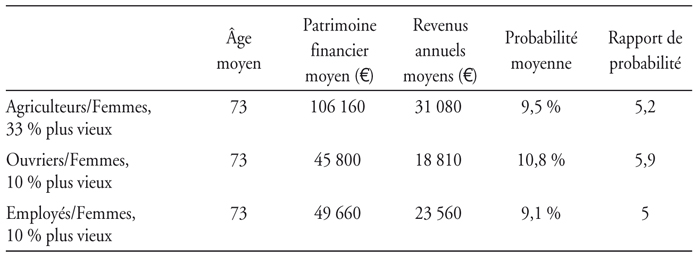
Ces résultats nous permettent d'identifier les catégories de population qui sont les plus susceptibles de souscrire : les femmes-ouvriers, les femmes-employés et les femmes-agriculteurs. Ainsi, appartenir à la catégorie des femmes-ouvriers donne 2,7 fois plus de chance de souscrire que les individus de la population générale. Ce ratio est de 2,9 pour les femmes-agriculteurs et 2,2 pour les femmes-employés. Nous allons améliorer notre ciblage en examinant les individus les plus riches en termes de « patrimoine financier » ainsi que les plus âgés, au sein de ces catégories. Les résultats précédents sont renforcés. Les femmes-ouvriers les 10 % les plus riches2 ont 5,8 fois plus de chance (4 fois et 5,2 fois plus de chance pour les femmes-employés et les femmes-agriculteurs, respectivement) de souscrire que les individus de la population générale. L'observation des tranches supérieures relatives aux âges, concernant les femmes-agriculteurs, les femmes-ouvriers et les femmes-employés, restitue les ratios suivants : 5,2, 5,9 et 5, respectivement.
Discussion
Le fait que les catégories « agriculteurs », « ouvriers » et « employés » ont chacune une probabilité plus élevée de contracter une assurance dépendance peut être interprété de différentes manières.
Un comportement rationnel ?
Une première interprétation nous amène à penser que les assurés adoptent un comportement que nous pouvons qualifier de comportement rationnel. Les ouvrières et les employées sont davantage susceptibles que les cadres supérieurs d'entrer en dépendance (Mormiche et Boissonnat, 2003). Les femmes ont une probabilité d'avoir besoin de soins-dépendance plus élevée et pour une durée moyenne plus longue. Cette probabilité est plus élevée pour deux raisons. La première ou facteur biologique induit à chaque âge chez elles une probabilité plus forte de basculer vers la dépendance. La seconde, liée à l'hygiène de vie pour les anciennes générations ou facteur de longévité, est synonyme d'une espérance de vie plus importante. Les femmes ont plus de chance d'être confrontées à la dépendance au cours de leur vie, cela avec un risque accru d'être alors seule ou veuve en fin de vie, risque se combinant à une perte de revenus non négligeable ou à un risque d'insolvabilité. Par ailleurs, elles supportent un risque financier plus important dans la mesure où elles reçoivent des pensions plus faibles que les hommes (979 euros pour les femmes contre 1 625 euros pour les hommes en 2004). De plus, pour les femmes de ces catégories sociales qui possèdent un patrimoine financier plus important que la moyenne de leur catégorie, il est fort probable que celui-ci soit entièrement consommé dans le financement des soins dépendance.
Les femmes des classes populaires (donc possédant de faibles retraites ou revenus) à patrimoine conséquent sont celles qui ont le plus à perdre si le risque dépendance se réalise. Il est donc rationnel de leur part de s'assurer davantage que la moyenne de la population car elles supportent un risque financier plus élevé. Comme elles ont une forte probabilité d'entrer en dépendance pour une durée de quatre ans en moyenne et que leur patrimoine moyen reste faible par rapport aux catégories des cadres, elles auront une forte probabilité de consommer tout leur patrimoine en cas de dépendance et ainsi de ne rien laisser à leurs descendants.
Perception du risque, aversion et antisélection
Même si nos données ne nous permettent pas de statuer directement sur le fait de savoir s'il existe ou non de la sélection adverse sur le marché de l'assurance dépendance, un certain nombre d'éléments nous permettent de confirmer les résultats de Costa-Font et Font Vilalta (2006), de Costa-Font et Rovira-Forns (2008) et de Finkelstein et McGarry (2003) qui montrent que la demande d'assurance dépendance est très fortement liée à la perception que l'individu a du risque en général, du risque dépendance en particulier et du risque financier associé.
La représentation subjective de la survenue du risque dépendance est très importante, d'après Finkelstein et McGarry (2003). Sur données américaines, ils observent (2006) que ce sont les individus les plus prudents qui s'assurent et pas forcément ceux qui ont le plus de risque objectif d'entrer en dépendance. Même si ces femmes ont un risque de perte financière plus important en cas de survenue de la dépendance, ont-elles un risque objectif plus important d'entrer en dépendance ? Sur données américaines, les résultats de Sindelar (1982) montrent que les femmes dépensent en moyenne 50 % de plus en soins médicaux et restent en moyenne 50 % de temps en moins hospitalisées que les hommes. Les données américaines et françaises (Insee, enquête HID – Handicap Incapacité Dépendance, 2001) montrent que la fréquence d'entrée en dépendance pour un âge fixé est plus élevée chez les femmes que chez les hommes. Il est possible qu'indépendamment de leur connaissance d'un risque supérieur, cette clientèle prenne des précautions en matière de prévention dans le domaine de la santé supérieure à la moyenne, ce qui rejoint la notion de représentation subjective du risque évoquée par Finkelstein et McGarry (2003 et 2006) et Plisson (2009).
Le travail de Sindelar (1982) a montré que le fait d'être une femme et le fait d'être âgée sont des facteurs prédisposant à l'aversion au risque et à la souscription d'assurance. Nos résultats confirment les résultats de Costa-Font et Rovira-Forns (2008). Dans leur enquête sur les préférences déclarées en matière de souscription, ils constatent que les personnes qui ont une perception claire du risque dépendance et qui sont averses au risque sont le plus souvent des femmes et que ce sont elles qui déclarent le plus vouloir contracter une assurance dépendance. Les femmes âgées appartenant aux catégories « ouvriers » et « employés » et possédant un patrimoine supérieur à la moyenne de la catégorie semblent avoir mieux compris ce risque que d'autres catégories. Elles ont peut-être mieux analysé ce risque car elles seraient davantage conscientes que les hommes de leur niveau de probabilité associé (en outre plus élevé) d'avoir besoin d'assurance dépendance. Cela étant peut-être lié au fait qu'elles ont bien compris que le risque financier qu'elles subiraient en cas de survenue de la dépendance serait très élevé. Ce type de comportements nous laisse penser que les comportements d'antisélection pourraient être à l'œuvre sur le marché de la dépendance. Nous pouvons d'ores et déjà noter que leur risque en termes de fréquence est substantiellement plus élevé que celui des hommes (Insee, enquête HID, 2001). Étant donné que les hommes et les femmes payent la même prime d'assurance, les femmes seraient plus incitées à souscrire que les hommes.
L'altruisme
Plus le patrimoine est important, plus la probabilité de s'assurer augmente (modèle simple). Cet effet est particulièrement important chez les agriculteurs et les ouvriers et chez les femmes-ouvriers (modèle avec interaction). Ce résultat est intéressant car il confirme l'hypothèse altruiste selon laquelle les individus s'assurent contre la dépendance pour protéger l'héritage qu'ils veulent transmettre à leurs enfants (Pauly, 1990). Cette hypothèse serait d'autant plus vérifiée que l'héritage à transmettre serait peu élevé. Nous confirmons ici l'hypothèse selon laquelle les gens qui s'assurent contre la dépendance sont des gens plus prévoyants que la moyenne (Finkelstein et McGarry, 2003). Afin de transmettre un héritage intact, ils préfèrent s'assurer contre la dépendance. Il est intéressant de noter que dans le modèle avec interaction, en ce qui concerne le patrimoine des catégories aisées, tel celui des cadres supérieurs, cela ne représente pas un facteur positif de souscription. Le comportement altruiste relevé dans la littérature sur la dépendance ne s'appliquerait pas aux catégories aisées car leur patrimoine étant plus élevé, les soins de dépendance ne l'entameraient qu'à la marge. Il en restera suffisamment pour le transmettre. Ce n'est pas le cas des ouvriers et des employés pour qui les soins de dépendance risquent de consommer la majorité, voire la totalité du patrimoine à transmettre. Cette différence de comportement entre catégories sociales différentes pourrait expliquer les résultats contradictoires donnés par les différentes études. Nos résultats sont en contradiction avec ceux de Sloan et Norton (1997), selon qui les gens qui laissent un héritage ne s'assurent pas contre la dépendance.
Si nous prenons la CSP comme un indicateur du niveau d'éducation : dans notre étude, plus le niveau d'éducation est faible (ouvriers ou employés), plus la probabilité de souscrire est élevée. Les ouvriers ont 2,5 fois plus de chance de souscrire une assurance dépendance que les non-ouvriers et les employés ont 1,6 fois plus de chance que les non-employés, les cadres supérieurs ont 2,5 fois moins de chance de souscrire une assurance dépendance. Nous pourrions expliquer notre résultat en reprenant l'hypothèse de l'altruisme que nous avons utilisée pour le patrimoine (d'ailleurs dans le modèle avec interactions, les variables de croisement entre le patrimoine et respectivement les catégories « agriculteurs », puis « ouvriers » sont significatives) : il semble que c'est pour pouvoir léguer un héritage limité que les ouvriers et les employés s'assurent contre la dépendance de peur que les soins de dépendance leur fassent dépenser tout le patrimoine qu'ils auraient voulu léguer. Ainsi, ce sont les catégories « âgés », « employés », « ouvriers » et « agriculteurs » qui souscrivent le plus à l'assurance dépendance. Au sein de ces catégories, ce sont celles qui présentent les patrimoines au-dessus de la moyenne qui souscrivent le plus.
Ces résultats nous laissent penser que l'assurance dépendance a le potentiel pour devenir un produit de masse (c'est-à-dire pas forcément réservée aux plus fortunés ou aux personnes les plus aisées et éduquées) au même titre que la complémentaire santé, si sa souscription par la classe « ouvriers » et la classe « employés » se généralisait.
Nos résultats montrent que la catégorie de la population qui s'assure le plus contre la dépendance semble peu sensible aux prix malgré sa CSP. Plus l'âge augmente, plus la souscription à l'assurance dépendance augmente, mais plus son prix augmente également. Aussi, cette étude nous amène à poser l'hypothèse que l'assurance dépendance pourrait être perçue comme un moyen d'assurer son patrimoine, en particulier chez les femmes des classes ouvrières et « employés » (donc possédant des faibles retraites ou revenus) possédant un patrimoine modeste, qui seraient celles qui auraient le plus à perdre si le risque dépendance survenait.
Conclusion
La catégorie de la population qui s'assure contre la dépendance est très particulière, elle semble peu sensible aux prix malgré sa « CSP populaire » car ayant à supporter des coûts élevés en cas de survenance, et elle serait averse au risque. Cette étude nous amène à conjecturer que ce sont les personnes qui perçoivent le plus le risque dépendance à travers la perception du risque d'insolvabilité associé qui s'assurent le plus. L'explication par le déficit moyen de perception (à la fois du risque de survenance et du risque financier induit par la survenance) semble être une piste crédible pour expliquer le faible taux moyen de souscription. Les personnes qui s'assurent contre la dépendance n'ont pas un déficit de perception du risque, au contraire, on pourrait même dire qu'elles ont probablement une bonne estimation du risque pour elles-mêmes. Une campagne d'information sur le risque dépendance pourrait donc permettre aux individus de mieux percevoir le risque dépendance et donc de davantage s'assurer. Cette hypothèse est conforme aux résultats de Doerpinghaus et Gustavson (2002) qui montrent que plus la part des personnes âgées dans la population et la part des personnes en institutions est importante dans un État américain, plus les individus contractent des assurances dépendance. Comme si la présence d'une importante population ayant reçu des soins de dépendance faisait prendre conscience au reste de la population des enjeux induits par les soins de dépendance. Les travaux de Sloan et al. (2003) montrent que plus les individus ont dans leur entourage familial ou amical quelqu'un de dépendant, plus ils souscrivent à des assurances dépendance, plus ils perçoivent ce que signifie le risque financier lié à la dépendance. C'est donc l'ignorance du risque qui semble être le principal facteur de non-souscription à l'assurance dépendance en général. Il « faut » posséder un certain nombre de caractéristiques sociodémographiques pour percevoir ce risque : être une femme, des classes populaires, âgée, etc., ces caractéristiques étant liées aux caractéristiques de ceux qui perdent le plus en cas de survenance de la dépendance. Il y aurait donc deux leviers de développement possible de ce marché : une meilleure information sur les coûts à la charge des individus et sur les risques de survenance de la dépendance. Cette meilleure information sur les coûts permettrait de faire agir la fibre altruiste des individus si ceux-là veulent transmettre un héritage complet à leurs enfants, en particulier pour les classes ouvrières et « employés ». Pour les classes plus aisées, des incitations fiscales comme préconisées par Costa-Font et Font Vilalta (2006) pourraient peut-être permettre un meilleur développement du marché. Mais les préférences des individus, notamment la préférence pour le présent, restent un frein au développement du marché (Fontaine et al., 2015).